本文成品,一个简易 RAG 应用,网址为 https://htmovies.vercel.app/,检索需梯子
假设我们现在有一万个电影的文字描述,如何根据用户的搜索,推荐给用户最相关的几个电影?比如,用户输入「NASA 努力救一个困在火星的宇航员」,那我们肯定会导出《火星救援》。如何实现呢?
办法是,假设我们有一个神奇的工具,你可以把它想象成一张网。任何一串文字通过它之后,都会变成一个高维空间里的一个向量,也就是高维空间里的一个坐标。然后我们让这一万条电影的文字描述经过这张网,我们得到一万个坐标。用户输入搜索,我们让这个搜索也经过这张网,得到一个坐标。最后的结果,我们计算这个搜索对应的坐标与每一个电影坐标的余弦相似度 (Cosine Similarity),然后找到结果最大的几个,就是我们的搜索结果。
这里涉及到一个问题。如果我们把每串文字经过网后的结果看成是一个坐标,那么寻找相似的点,可以用欧几里得距离 。如果我们把每个结果看成是一个向量,那么需要用余弦相似度。那具体用什么方法呢?OpenAI Platform 给出的答案是:
We recommend cosine similarity. The choice of distance function typically doesn't matter much.
OpenAI embeddings are normalized to length 1, which means that:
- Cosine similarity can be computed slightly faster using just a dot product
- Cosine similarity and Euclidean distance will result in the identical rankings
也就是说,先把每一个点的坐标归一化,也就是确保每一个向量长度为 1,然后,不管我们用欧几里得距离还是余弦相似度,不影响搜索结果。为什么?我们来证明一下:
归一化之后,余弦相似度为:
$$\text{Cosine Similarity(A, B)} = \frac{\vec{A} \cdot \vec{B}}{|A||B|} = \sum_{i=1}^{n}a_i b_i$$
$$\begin{aligned} \text{Euclidean Distance(A, B)}^2 & = (a_1 - b_1)^2 + (a_2 - b_2)^2 + ... + (a_n - b_n)^2 \\ & = (a_1 + a_2 + ... a_n)^2 + (b_1 + b_2 + ... b_n)^2 - 2(a_1 b_1 + a_2 b_2 + ... + a_n b_n)\\ & = |A|^2 + |B|^2 - 2\sum_{i=1}^{n}a_i b_i \\ & = 2 - 2 \cdot \text{Cosine Similarity(A, B)} \end{aligned}$$
也就是说这两个是完全正相关的关系,余弦相似度越大,欧几里得距离也越大。所以两者虽然具体数值不同,但是排序的结果一样。那为什么 OpenAI 推荐用余弦相似度呢?因为它的运算更少。我们来看:
$$\text{Cosine Similarity(A, B)} = \sum_{i=1}^{n}a_i b_i$$
这里我们只需要 $n$ 次乘法和 $n-1$ 次加法。
$$\text{Euclidean Distance(A, B)} = \sqrt{\sum_{i=1}^n (a_i - b_i)^2}$$
我们需要:
$n$次减法$n$次平方$n - 1$次加法$1$次开方
虽然时间复杂度都是 $O(n)$,但欧几里得距离明显比余弦相似度运算量要大。
回到正题,这张神奇的网是「向量表示 (Embedding)」。比较知名的是 Bert,它比较大,我们这里用 Sentence Transformers。更神奇的是,如果我们用多语言的模型,比如 paraphrase-multilingual-mpnet-base-v2,那即使我们的训练数据是英文的,我们也可以用中文搜索。不过,多语言模型也比较大,我们这里不用。我们用比较小的 all-MiniLM-L6-v2。
另外,我们用 FAISS (Facebook AI Similarity Search) 计算余弦相似度,因为这比较快。
关于 Embedding Models,请参考 Ollama 的这篇教程 。
原始数据 #
数据下载地址:https://hongtaoh.com/files/tmdb-movies.csv 。
最原始的数据来自于 Kaggle 上的 Full TMDB Movies Dataset 2024 (1M Movies) ,包含一百万条电影数据。我检查了一些关键条目,去掉了在这些条目上信息不全的电影,最后得到大约一万条电影数据。
import pandas as pd
import numpy as np
import uuid
Show Code
# 去掉了关键条目上信息不全的电影,最后得到大约一万条电影数据
# df = pd.read_csv('./data/tmdb_large.csv')
# corecols = ['id', 'title', 'vote_average', 'vote_count', 'release_date',
# 'revenue', 'runtime', 'backdrop_path', 'budget', 'homepage', 'original_language', 'overview',
# 'popularity', 'poster_path', 'tagline', 'genres',
# 'production_companies', 'production_countries', 'spoken_languages',
# 'keywords']
# df_clean = df.dropna(subset=corecols)
# df_clean.to_csv('../static/files/tmdb-movies.csv', index=False)
df = pd.read_csv('../static/files/tmdb-movies.csv')
df.shape
df.columns
df[['id', 'title', 'overview', 'revenue', 'poster_path']].head(5)
| id | title | overview | revenue | poster_path | |
|---|---|---|---|---|---|
| 0 | 27205 | Inception | Cobb, a skilled thief who commits corporate es... | 825532764 | /oYuLEt3zVCKq57qu2F8dT7NIa6f.jpg |
| 1 | 157336 | Interstellar | The adventures of a group of explorers who mak... | 701729206 | /gEU2QniE6E77NI6lCU6MxlNBvIx.jpg |
| 2 | 155 | The Dark Knight | Batman raises the stakes in his war on crime. ... | 1004558444 | /qJ2tW6WMUDux911r6m7haRef0WH.jpg |
| 3 | 19995 | Avatar | In the 22nd century, a paraplegic Marine is di... | 2923706026 | /kyeqWdyUXW608qlYkRqosgbbJyK.jpg |
| 4 | 24428 | The Avengers | When an unexpected enemy emerges and threatens... | 1518815515 | /RYMX2wcKCBAr24UyPD7xwmjaTn.jpg |
movie_ids = df.id.tolist()
movie_overviews = df.overview.tolist()
# Create dictionaries
Id2Title = dict(zip(df.id, df.original_title))
Id2Overview = dict(zip(df.id, df.overview))
Id2PosterPath = dict(zip(df.id, df.poster_path))
Id2Revenue = dict(zip(df.id, df.revenue))
向量表示 #
from sentence_transformers import SentenceTransformer
from sklearn.preprocessing import normalize
model = SentenceTransformer('all-MiniLM-L6-v2')
from typing import List, Dict, Tuple
import faiss
def get_movie_embeddings(
movie_ids:List[str],
movie_overviews:List[str],
model: SentenceTransformer,
batch_size: int = 32,
) -> Dict[str, np.ndarray]:
"""
Generates normalized embeddings for movie overviews.
Args:
movie_ids: List of movie IDs.
movie_overviews: List of movie overviews.
model: Embedding model (e.g., SentenceTransformer).
batch_size: Batch size for processing.
Returns:
Dictionary mapping movie IDs to normalized embeddings.
"""
if len(movie_ids) != len(movie_overviews):
raise ValueError("movie_ids and movie_overviews must have the same length.")
all_embeddings = []
for i in range(0, len(movie_ids), batch_size):
batch_movies = movie_overviews[i:i+batch_size]
try:
batch_embeddings = model.encode(batch_movies)
all_embeddings.extend(batch_embeddings)
except Exception as e:
print(f"Error encoding batch {i}: {e}")
raise
try:
all_embeddings_np = np.array(all_embeddings) #added numpy array conversion.
normalized_embeddings = normalize(all_embeddings_np, axis=1, norm='l2')
except Exception as e:
print(f"Error normalizing embeddings: {e}")
raise
# Create a hashmap; otherwise we cannot map from embeddings to distinct movies
# starting from Python 3.7, dictionaries (dict) preserve insertion order by default.
# Therefore, there is no need to sort
movie_embeddings = dict(zip(movie_ids, normalized_embeddings))
return movie_embeddings
movie_embeddings = get_movie_embeddings(movie_ids, movie_overviews, model)
搜索 #
def prepare_faiss_index(
movie_embeddings: Dict[str, np.ndarray]) -> Tuple[faiss.Index, List[str]]:
"""
Prepares a FAISS index from movie embeddings.
Args:
movie_embeddings: Dictionary of movie IDs to normalized embeddings.
Returns:
Tuple of (FAISS index, ordered list of movie IDs)
"""
movie_ids = list(movie_embeddings.keys())
embeddings = np.array([movie_embeddings[mid] for mid in movie_ids])
#create and populate the index
dim = embeddings.shape[1]
index = faiss.IndexFlatIP(dim)
index.add(embeddings)
return index, movie_ids
def search_movies(
faiss_index: faiss.Index,
movie_ids: List[str],
id2title_dict: Dict[int, str],
user_query: str,
model: SentenceTransformer,
k: int = 10,
) -> Tuple[List[str], List[float]]:
"""
Searches movies based on a user query using Faiss and cosine similarity.
Args:
faiss_index: Pre-built FAISS index
movie_ids: Ordered list of movie IDs that corresponds to the index
id2title_dict: Dict mapping from movie IDs to movie titles
user_query: The user's search query.
model: SentenceTransformer model.
k: Number of results to return.
Returns:
Tuple, top K movie titles and their associated cosine similarity scores
"""
#embed and normalize the user query
query_embedding = model.encode([user_query])
normalized_query_embedding = normalize(query_embedding, axis = 1, norm = 'l2')
#search the index
similarities, indices = faiss_index.search(normalized_query_embedding, k)
#retrieve movie ids and similarity scores
top_k_ids = [movie_ids[i] for i in indices[0]]
top_k_titles = [id2title_dict[x] for x in top_k_ids]
top_k_scores = similarities[0]
return top_k_titles, top_k_scores
faiss_index, movie_ids = prepare_faiss_index(movie_embeddings)
user_query = "NASA tried to rescue an astronaut stranded on Mars."
results = search_movies(
faiss_index,
movie_ids,
Id2Title,
user_query,
model
)
results
走向云端 #
现在的问题是,一个不懂计算机的用户,需要搜索电影,怎么办?他不会下载数据,也不会运行上面的代码。这是大部分用户的现状。解决办法是把我们算好的 movie_embedding 存在云端。
我首先想到的一个办法是把我们的电影原始数据以及我们得到的向量表示 (Embedding) 储存在 MongoDB。然后,在一个 Web App (网页应用程序,你可以理解为一个网站) 上,把这个数据和向量表示下载下来,然后根据用户的搜索,给出最相似的电影推荐。这个办法可行,但是很慢。
更好的办法是使用专门用来做向量搜索的数据库。这些向量库有自己的储存和搜索方法,我们不需要用上面的 FAISS。只需要把所有的 embedding 存入。搜索的时候,给一个向量,这些向量库会进行优化搜素,快速给出结果。
Qdrant #
我先试了一下 Qdrant 。
免费版暂时够用了。
首先需要运行:
pip install qdrant-client
import os
# `pip install python-dotenv` first
from dotenv import load_dotenv
load_dotenv()
url = os.getenv("QDRANT_MOVIE")
api_key = os.getenv("QDRANT_API_KEY")
from qdrant_client import QdrantClient
from qdrant_client.models import VectorParams, Distance
import uuid
qdrant_client = QdrantClient(
url=url,
api_key=api_key
)
try:
qdrant_client.delete_collection(collection_name='movies')
print("Deleted existing collection")
except Exception as e:
print(f"Collection might not exist yet: {e}")
# Create the collection first
vector_size = len(next(iter(movie_embeddings.values())))
qdrant_client.create_collection(
collection_name="movies",
vectors_config=VectorParams(
size=vector_size,
distance=Distance.COSINE
)
)
# Qdrant requires ids to be strs, not int
def int2uuid(i:int):
return str(uuid.uuid5(uuid.NAMESPACE_DNS, str(i)))
batch_size = 1_000
for i in range(0, len(movie_ids), batch_size):
batch_ids = movie_ids[i:i+batch_size]
batch_vectors = []
for movie_id in batch_ids:
batch_vectors.append({
'id': movie_id,
'vector': movie_embeddings[movie_id].tolist(),
'payload': {
'title': Id2Title.get(movie_id, ''),
'overview': Id2Overview.get(movie_id, ""),
'poster_path': Id2PosterPath.get(movie_id, ""),
'revenue': Id2Revenue.get(movie_id, "")
}
})
qdrant_client.upsert(
collection_name = 'movies',
points = batch_vectors
)
print(f"Uploaded batch {i//batch_size + 1}/{(len(movie_ids)-1)//batch_size + 1}")
首先,为什么我们不一个一个上传?
- 第一,速度慢。每一个
upsert都是一次独立的网络请求。网络请求会带来一些固定的开销,比如建立连接、发送请求头、等待服务器响应等。如果逐个上传,这些开销会累积起来,导致传输速度非常慢。 - 第二,服务器端数据库的处理速度。向量库的设计就是为了批量处理。批量上传可以使数据库更快完成数据处理 (建立索引和其他操作)。逐个上传会增加数据库的负担,降低效率。
那为什么不一次把一万个上传上去,而是分成 11 个批次?
- 第一,一般 API 每次请求都有文件大小限制,一万条数据我怕超额。
- 第二,内存消耗,大型请求无论是在客户端还是服务器端都需要大量内存。一次上传所有数据可能导致内存不足,引发程序崩溃或降低性能。
- 第三,网络稳定性。大型请求容易造成网络中断。如果上传过程中出现中断,那整个操作都失败了,我们一条数据都没上传成功,需要从头开始。
def search_qdrant(
query_text:str, model:SentenceTransformer, top_k:int = 5):
query_embedding = model.encode([query_text])
normalized_query = normalize(query_embedding, axis = 1, norm='l2')
results = qdrant_client.query_points(
collection_name = 'movies',
query=normalized_query[0].tolist(),
limit=top_k
)
movies = []
for result in results.points:
movies.append({
'title': result.payload['title'],
'overview': result.payload['overview'],
'similarity_score': result.score
})
return movies
更多的 Qdrant Search 请参考官方文档:https://qdrant.tech/documentation/concepts/search/ 。
user_query = "NASA tried to rescue an astronaut stranded on Mars."
search_qdrant(query_text=user_query, model=model)
Pinecone #
也可以用 Pinecone 。首先,
pip install pinecone
from pinecone import Pinecone, ServerlessSpec
pinecone_api_key = api_key = os.getenv("PINECONE_API_KEY")
pc = Pinecone(api_key=pinecone_api_key)
index_name = "movies"
# Get the list of index names from the dictionaries
existing_indexes = [index["name"] for index in pc.list_indexes()]
if index_name in existing_indexes:
print(f"Deleting existing index: {index_name}!")
pc.delete_index(index_name)
else:
print(f"Index '{index_name}' does not exist.")
vector_size = len(next(iter(movie_embeddings.values())))
pc.create_index(
name=index_name,
dimension=vector_size, # Replace with your model dimensions
metric="cosine", # Replace with your model metric
spec=ServerlessSpec(
cloud="aws",
region="us-east-1"
)
)
# Get the index object
index = pc.Index(index_name)
batch_size = 1_000
for i in range(0, len(movie_ids), batch_size):
batch_ids = movie_ids[i:i+batch_size]
batch_vectors = []
for movie_id in batch_ids:
batch_vectors.append({
'id': str(movie_id),
'values': movie_embeddings[movie_id].tolist(),
'metadata':{
'title': Id2Title.get(movie_id, ''),
'overview': Id2Overview.get(movie_id, ""),
'poster_path': Id2PosterPath.get(movie_id, ""),
'revenue': Id2Revenue.get(movie_id, "")
}
})
index.upsert(vectors = batch_vectors)
print(f"Uploaded batch {i//batch_size + 1}/{(len(movie_ids)-1)//batch_size + 1}")
def search_pinecone(
query_text:str,
model:SentenceTransformer,
top_k:int = 5):
query_embedding = model.encode([query_text])
normalized_query = normalize(query_embedding, axis = 1, norm='l2')
results = index.query(
vector=normalized_query[0].tolist(),
top_k=top_k,
include_metadata=True
)
# Format results
movies = []
for match in results['matches']:
movies.append({
"title": match['metadata']['title'],
"overview": match['metadata']['overview'],
"similarity_score": match['score']
})
return movies
user_query = "NASA tried to rescue an astronaut stranded on Mars."
search_pinecone(query_text=user_query, model=model)
其他选择 #
- Chroma 看上去也不错,但是需要 self-host,比较麻烦。
- Azure Cosmos DB
- Milvus 和 zilliz 一起。
构建 API #
现在的问题是,我们依然是用代码才能做这些事情。而真正的用户大部分是不懂代码的。我们如何让他们直接输入搜索文本,然后给他们返回结果?这就需要用到 API。也就是说,把搜索文本向量化、搜索、返回搜索结果,都在网络上完成。
比如,打开 https://htmovies.vercel.app/api/search?q=%22NASA%22&k=5 。你会看到 JSON 结果。这就是 API 的作用。
我用 FastAPI 做了一个 API。代码如下:
Show Code
from fastapi import FastAPI, HTTPException, Query
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
from typing import List, Optional
from sentence_transformers import SentenceTransformer
from sklearn.preprocessing import normalize
from qdrant_client import QdrantClient
import os
from dotenv import load_dotenv
import numpy as np
# Load environment variables
load_dotenv()
# Initialize FastAPI app
app = FastAPI(
title="Movie Search API",
description="Search for movies using semantic similarity",
version="1.0.0"
)
# Add CORS middleware to allow cross-origin requests (important for web clients)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # Allows all origins
allow_credentials=True,
allow_methods=["*"], # Allows all methods
allow_headers=["*"], # Allows all headers
)
# Initialize Qdrant client
qdrant_url = os.getenv("QDRANT_MOVIE")
qdrant_api_key = os.getenv("QDRANT_API_KEY")
qdrant_client = QdrantClient(
url=qdrant_url,
api_key=qdrant_api_key
)
# Initialize the SentenceTransformer model (load it only once at startup)
model = SentenceTransformer('all-MiniLM-L6-v2')
# Define response model for better documentation and type checking
class MovieSearchResult(BaseModel):
title: str
overview: str
imdb_id: str
similarity_score: float
class SearchResponse(BaseModel):
movies: List[MovieSearchResult]
query: str
@app.get("/")
async def root():
return {
"message": "Welcome to Movie Search API!",
"docs": "/docs",
"usage": "Send GET requests to /search?query=your search text"
}
@app.get("/search", response_model=SearchResponse)
async def search_movies(
query: str = Query(..., description="The search query to find similar movies"),
top_k: int = Query(5, ge=1, le=50, description="Number of results to return")
):
try:
# Encode the query text
query_embedding = model.encode([query])
normalized_query = normalize(query_embedding, axis=1, norm='l2')
# Search in Qdrant
results = qdrant_client.search(
collection_name='movies',
query_vector=normalized_query[0].tolist(),
limit=top_k
)
# Format the results
movies = []
for result in results:
movies.append(MovieSearchResult(
title=result.payload['title'],
overview=result.payload['overview'],
imdb_id=result.payload['imdb_id'],
similarity_score=result.score
))
return SearchResponse(
movies=movies,
query=query
)
except Exception as e:
# Log the error (you might want to use a proper logging system)
print(f"Error during search: {e}")
raise HTTPException(status_code=500, detail=f"Search failed: {str(e)}")
@app.get("/health")
async def health_check():
"""Health check endpoint to verify the service is running"""
return {"status": "healthy"}
在本地运行没问题:
本地运行 FastAPI
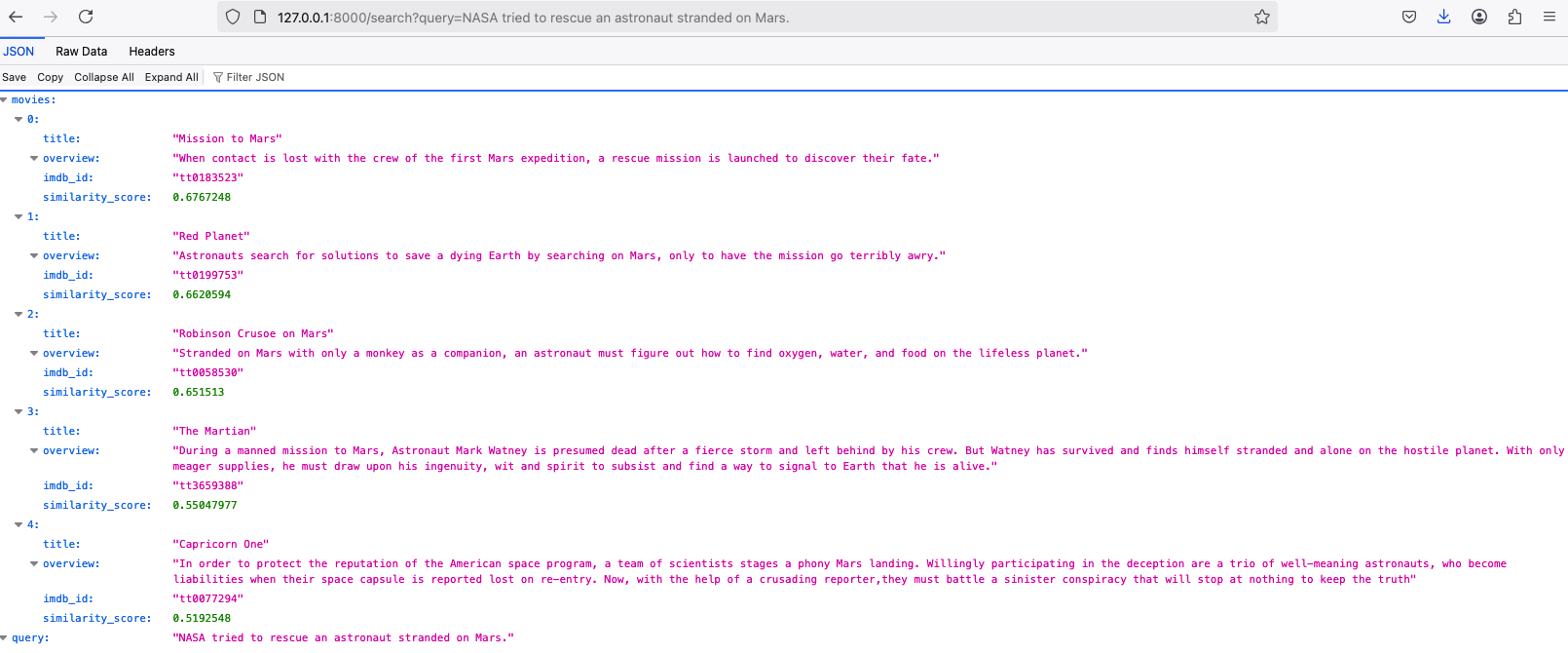
本地运行 FastAPI
但是部署到 Vercel 没成功:
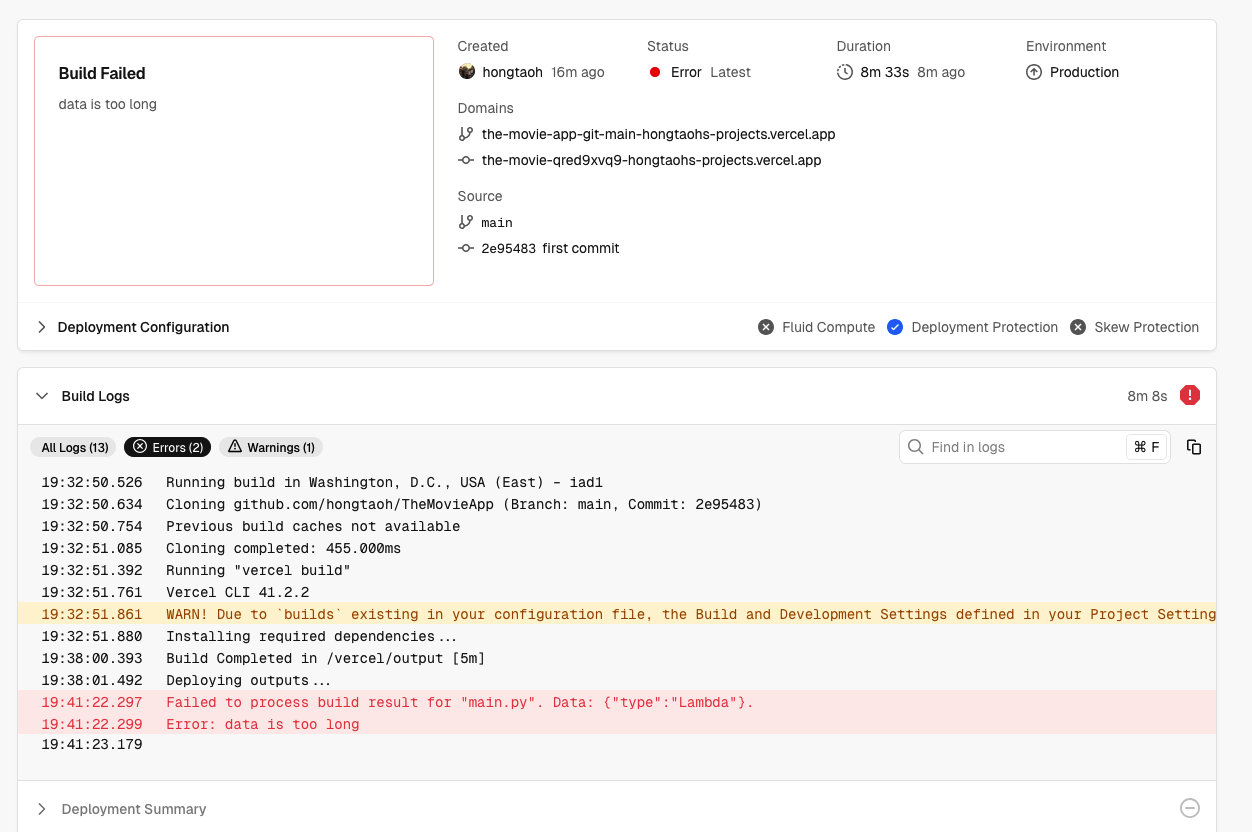
Vercel 部署 FastAPI 失败
这是因为我们需要的包太多了
fastapi[standard]
sentence_transformers
qdrant_client
python-dotenv==1.0.0
scikit-learn==1.3.2
超过了 Vercel 允许的大小限制。
最好的办法是找一个适合 ML/LLM 项目的部署平台。我试过免费的 render.com 但是太慢了,因为有休眠限制。
第一个解决办法是用封装好的 embedding,比如 DeepSeek OpenAI Gemini 等,这样就不需要 sentence_transformer 这么大的包。按道理就可以部署到 Vercel。
第二个解决办法是使用专业的 API 部署平台,比如 Google Cloud Platform, Azure, AWS 或者小公司,比如 fly.io, railway.app, heroku.com 等。
选择大语言模型 #
具体用哪条路需要结合具体的需求。
如果使用第一种办法,也就是用大公司提供的 embedding 接口,好处是这意味着我都不需要有后端 (backend)。为什么?因为原始数据的存储和向量搜索都在向量库进行,那我用前端直接处理用户搜索文本,然后导出结果,只需要和 embedding 接口交流就好,根本不需要自己部署后端。
第二种办法的好处是,如果是一个大型项目,需要用户注册、登陆,那一般情况下就需要自己部署 API 了。那既然自己都部署了,何不一步到位,用 Python 进行向量搜索?
我这里暂时用第一种办法。理由有两个:1)我想试一下 DeepSeek 的 embedding;2)我暂时不需要用户注册、登陆。
开工!
我首先想到去 DeepSeek Platform 申请 API Key,但是发现 DeepSeek 暂未支持 embedding model 。
我目前想到的有以下几个:
- Google Gemini 。他家四天前刚出了 gemini-embedding-exp-03-07 ,我还挺想用一下。
- OpenAI Vector Embeddings ,老熟人了。不免费,但 embedding 这种一般不太贵。
- Cohere Embed ,有免费的额度 。
咱们来试一下 Google 吧。
import google.generativeai as genai
import os
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
genai.configure(api_key=GEMINI_API_KEY)
Show Code
#测试embedding
embedding_model = genai.embed_content(model="models/gemini-embedding-exp-03-07", content="test")
print(f"gemini-embedding-exp-03-07 的 output 维度为 {len(embedding_model['embedding'])}")
embedding_model = genai.embed_content(model="models/text-embedding-004", content="Where is France?")
print(f"text-embedding-004 的 output 维度为 {len(embedding_model['embedding'])}")
gemini-embedding-exp-03-07 效能好,但是它太大了啊,弃用之。使用 text-embedding-004 模型。
另外,我好奇 text-embedding-004 的结果是否已经归一化:
norm = np.linalg.norm(embedding_model['embedding'])
print(f"L2 范数:{norm}")
if np.isclose(norm, 1):
print("向量已进行 L2 归一化")
else:
print("向量未进行 L2 归一化")
def get_gemini_embeddings(texts:List[str]) -> np.ndarray:
embeddings = []
for text in texts:
response = genai.embed_content(
model="models/text-embedding-004",
content=text)
embeddings.append(response['embedding'])
return np.array(embeddings)
然后我们直接用上面的代码,只需要加入 get_gemini_embeddings 即可:
try:
qdrant_client.delete_collection(collection_name='movies_genai')
print("Deleted existing collection")
except Exception as e:
print(f"Collection might not exist yet: {e}")
# Create the collection first
embeddings = get_gemini_embeddings([movie_overviews[0]])
vector_size = len(embeddings[0])
qdrant_client.create_collection(
collection_name="movies_genai",
vectors_config=VectorParams(
size=vector_size,
distance=Distance.COSINE
)
)
Show Code
# batch_size = 100
# total_batches = (len(movie_ids) - 1)//batch_size + 1
# for i in tqdm(
# range(0, len(movie_ids), batch_size),
# total=total_batches,
# desc="Uploading batches"
# ):
# batch_ids = movie_ids[i:i+batch_size]
# batch_overviews = movie_overviews[i:i + batch_size]
# try:
# batch_embeddings = get_gemini_embeddings(batch_overviews)
# points = []
# for j, movie_id in enumerate(batch_ids):
# # Generate a UUID for each movie ID
# point_id = str(uuid.uuid4())
# points.append({
# 'id': point_id,
# 'vector': batch_embeddings[j].tolist(),
# 'payload': {
# 'title': Id2Title.get(movie_id, ''),
# 'overview': Id2Overview.get(movie_id, ""),
# 'imdb_id': movie_id,
# }
# })
# qdrant_client.upsert(
# collection_name = 'movies_gemini',
# points = points
# )
# time.sleep(1)
# except Exception as e:
# print(f"Error uploading batch {i //batch_size + 1}: {e}")
问题是太慢了。下面我们用到多线程并行计算。具体来说,是 Task parallelism。教程可以参考我写的 A Super Brief Introduction to Parallel Computing 。
需要注意的是,谷歌的限制是每分钟 1500 个请求。不要超过。
from concurrent.futures import ThreadPoolExecutor
import threading
from tqdm import tqdm
def process_one_batch(batch_ids, batch_overviews):
try:
batch_embeddings = get_gemini_embeddings(batch_overviews)
points = []
for j, movie_id in enumerate(batch_ids):
points.append({
'id': movie_id,
'vector': batch_embeddings[j].tolist(),
'payload': {
'title': Id2Title.get(movie_id, ''),
'overview': Id2Overview.get(movie_id, ""),
'poster_path': Id2PosterPath.get(movie_id, ""),
'revenue': Id2Revenue.get(movie_id, "")
}
})
qdrant_client.upsert(
collection_name = 'movies_genai',
points = points
)
return True
except Exception as e:
print(f"Error uploading batch: {e}")
return False
# #|code-fold:true
# batch_size = 180
# all_batches = []
# for i in range(0, len(movie_ids), batch_size):
# batch_ids = movie_ids[i:i+batch_size]
# batch_overviews = movie_overviews[i:i + batch_size]
# all_batches.append((batch_ids, batch_overviews))
# max_workers = 3 # 同时进行 3 个线程
# with ThreadPoolExecutor(max_workers=max_workers) as executor:
# results = list(tqdm(
# executor.map(lambda batch: process_one_batch(batch[0], batch[1]), all_batches),
# total=len(all_batches),
# desc="Uploading batches"
# ))
# # 统计成功数量
# successful_batches = results.count(True)
# print(f"成功处理 {successful_batches}/{len(all_batches)} 批次")

接下来,我们来试一下搜索。需要重新写 search_qdrant 因为我们需要用 Google-Gemini 来给搜索文本一个向量表示,而不是之前的 sentence_transformer 模型。
def search_qdrant(
query_text:str, top_k:int = 5):
# 使用 Google-Gemini 而不是我们之前的 model
query_embeddings = get_gemini_embeddings([query_text])
results = qdrant_client.query_points(
collection_name = 'movies_genai',
query=query_embeddings[0].tolist(),
limit=top_k
)
movies = []
for result in results.points:
movies.append({
'title': result.payload['title'],
'overview': result.payload['overview'],
'similarity_score': result.score
})
return movies
user_query = "NASA tried to rescue an astronaut stranded on Mars."
search_qdrant(query_text=user_query)
我们来看一下用中文怎么样:
user_query = "NASA尝试营救一名滞留在火星上的宇航员。"
search_qdrant(query_text=user_query)
text-embedding-004 无法很好地支持多语言。
重新构建 API #
我先试着用 FastAPI 重新做了一下,这次省去了 sentence-transformers 这么大的包,改用 Google Gemini 的 API 接口。代码在 https://github.com/hongtaoh/TheMovieApp
。API 网址是 https://the-movie-app-gamma.vercel.app/
。我们看到 API 部署成功,但是我试了一下,显示 Timedout,说明超过了 Vercel 允许的运算时间。毕竟是免费的。
我试了试 PythonAnywhere 和 Replit。前者实在是太远古,操作太复杂,我直接放弃。后者没有免费的部署选项。
结论就是,如果想使用 Python 作为后端,免费的部署服务几乎不存在。
构建 RAG #
RAG 听起来高大上,但其实我们上面已经完成了一大部分。在这里,我们如何用 RAG?
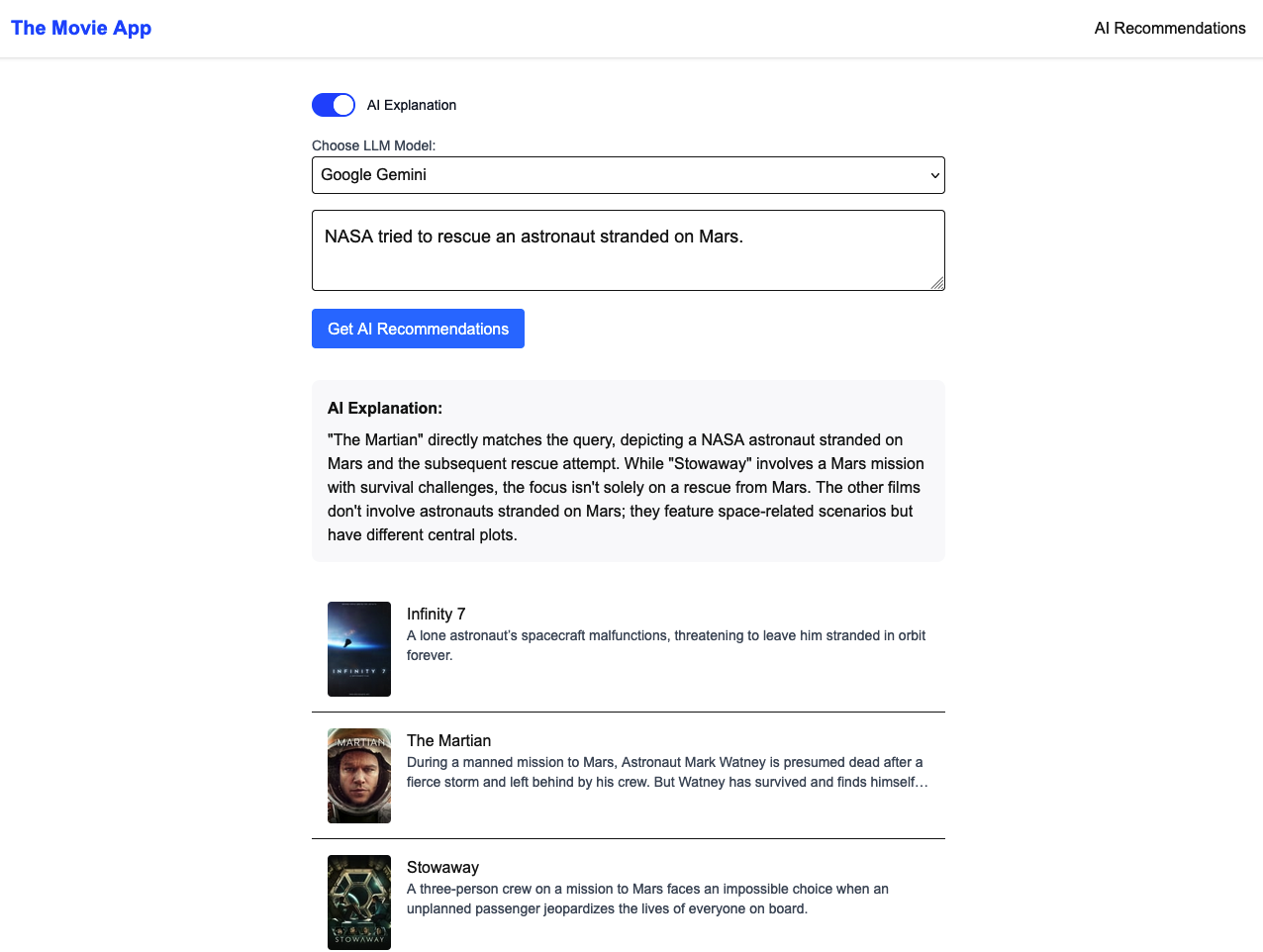
很简单。比如,一个用户搜索 “NASA tried to rescue an astronaut stranded on Mars.” 之后,我们可以返回结果,就像上面展示的那样。但是,我如果想用自然语言 (也就是人类语言) 解释为什么这些结果匹配用户的搜索,这就需要用到语言模型。这个过程就用到了 RAG。
具体怎么操作呢?很简单,就像你在 DeepSeek 上直接问:这是用户的搜索,“NASA tried to rescue an astronaut stranded on Mars.",这是结果,blablabla。请告诉我为什么结果匹配搜索。然后 DeepSeek 就会把答案给你。RAG 的作用是把这个过程整合起来、自动化。
为了演示具体怎么操作,在 DeepSeek + Claude 的帮助下,再加上我之前学过的一些零散的全栈知识,用 Next.js 做了一个很简单的网站应用:https://htmovies.vercel.app/ 。需要梯子。源代码在 https://github.com/hongtaoh/Movie_Recommendations_Easy 。
下面,我会一步一步介绍,这个是如何做出来的。即使你完全不懂 Next/React,大概也能看懂。
Next.js 的好处是,连后端的 API 接口都可以一起做好,
比如,你在浏览器输入
- https://htmovies.vercel.app/api/movies/27205
- https://htmovies.vercel.app/api/movies/random
- https://htmovies.vercel.app/api/movies/random?k=10
- https://htmovies.vercel.app/api/search?q=%22NASA%22&k=5
数据 #
第一步是把数据转换成 JSON 格式:
df[['id', 'overview', 'revenue', 'title', 'poster_path']].to_json(
'./data/movies.json', orient='records', indent=4)
安装 Node.js #
如果你还没下载,请到 https://nodejs.org/en 下载。
完成后,验证:
node -v
npm -v
cd 到自己的想要的路径,然后
新建 Next.js 项目 #
npx create-next-app@latest my-next-app
选择:
- TypeScript -> No
- ESLint -> Yes
- Tailwind CSS -> Yes
- src directory -> No
- App router -> Yes
- Turbopack -> No
- customize the import alias -> No
然后
cd my-next-app
接着在根目录创建 data 文件夹,然后把上面那个 json 文件放进去。
解释 #
如果你嫌麻烦,直接 git clone 我的源代码就好 https://github.com/hongtaoh/Movie_Recommendations_Easy。
我简单解释一下整个构架。
app/layout.js 这个主要负责整体的样式和目录。比如,The Movie App 和 AI Recommendations 这两个路径就是在这里创建的。之后如果需要用的 useContext 也最好在这里放 ContextProvider.
app/page.js 这是一进来后的主页面,展示了许多电影。这里面每一个电影,都是用 components/MovieCard.js 来制定样式的。
当我们选中其中任何一个电影后,就会进入具体电影的页面,这是由 app/movies/[id]/page.js 渲染的。
当我们点开 AI Recommendations,点击搜索后,具体的流程就是,我们先在 app/recommendation/page.js 中点击,然后 app/api/recommend/route.js 就会运行,连带着运行 lib/geminiEmbedding.js、lib/qdrant.js 和 lib/explain.js。然后结果返回 app/recommendation/page.js。
上面提到的 API 接口,也都是在 app/api 完成的。
这里简单说一下 Langchain。在 lib/explain.js 中我用了 langchain 而不是具体的 Gemini 或者 DeepSeek 的接口。这是因为,这样的话,换语言模型比较简单。这也是 langchain 的作用之一。
最后一次修改于 2025-06-03 • 编辑本页