数据处理中经常会用到四种基本的数据合并:Inner Join, Left Join, Right Join, Outer Join。下面我尝试用 SQL 以及两个简单的数据列表把这四个基本概念讲一下。
%load_ext sql
%sql sqlite:///:memory:生成数据 #
首先,我们生成两个简单的数据:Project 和 Employee。两个数据都有 employee_id 这个变量。
%%sql
CREATE TABLE Project (
project_id INT,
employee_id INT,
PRIMARY KEY (project_id, employee_id),
FOREIGN KEY (employee_id) REFERENCES Employee(employee_id)
);
-- Insert data into Project table
INSERT INTO Project (project_id, employee_id) VALUES
(1, 1),
(1, 2),
(1, 3),
(2, 1),
(2, 4); -- Only employees 1, 2, 3, and 4 are in projects%%sql
CREATE TABLE Employee (
employee_id INT PRIMARY KEY,
name VARCHAR(50),
experience_years INT
);
-- Insert data into Employee table
INSERT INTO Employee (employee_id, name, experience_years) VALUES
(1, 'Khaled', 3),
(2, 'Ali', 2),
(3, 'John', 1),
(4, 'Doe', 2),
(5, 'Alex', 4); -- Note: Employee 5 is not in the Project table+-------------+-------------+
| project_id | employee_id |
+-------------+-------------+
| 1 | 1 |
| 1 | 2 |
| 1 | 3 |
| 2 | 1 |
| 2 | 4 |
+-------------+-------------+Employee:
+-------------+--------+------------------+
| employee_id | name | experience_years |
+-------------+--------+------------------+
| 1 | Khaled | 3 |
| 2 | Ali | 2 |
| 3 | John | 1 |
| 4 | Doe | 2 |
| 5 | Alex | 4 |
+-------------+--------+------------------+INNER JOIN #
Inner Join 是取共有的:
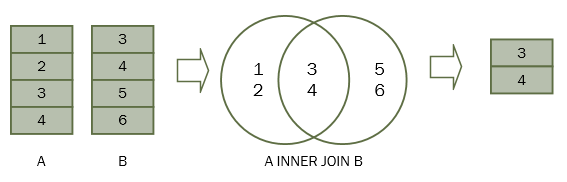
图片来源: https://www.sqltutorial.org/wp-content/uploads/2016/03/SQL-INNER-JOIN.png
Join 的时候,我们可以把表一加在表二上,也可以把表二加在表一上。对于 inner join 来说,这两个一样。我们两个都讲讲。
假如我们把 Employee 加在 Project 上,首先这个 key 是 employee_id,也就是两个表共有的一个变量,这个很好理解。第一步是把 Employee 这个表做成一个 Hashmap:
{
1: ['Khaled', 3],
2: ['Ali', 2],
3: ['John', 1],
4: ['Doe', 2],
5: ['Alex', 4]
}然后把这个 hashmap 对应到 Project 上。
或者,我们也可以把 Project 加到 Employee 上:
首先也是做一个 hashmap, 但是要注意,因为相同的 employee_id 可以对应多个 project_id,所以这个 hashmap 中的 value 需要是一个 list。
{
1:[1,2],
2:[1],
3:[1],
4:[2]
}然后把这个 hashmap 对应到 Employee 表上。这里有两点需要注意:
- 因为
employee_id = 1对应两个project_id,所以 Project 表中employee_id = 1那一行要重复一次。 - Project 中
employee_id = 5在我们这个 hashmap 中没有,所以在最后的结果中把这一行删除。
%%sql
SELECT p.project_id, p.employee_id, e.name, e.experience_years
FROM Project p
INNER JOIN Employee e
ON p.employee_id = e.employee_id;| project_id | employee_id | name | experience_years |
|---|---|---|---|
| 1 | 1 | Khaled | 3 |
| 1 | 2 | Ali | 2 |
| 1 | 3 | John | 1 |
| 2 | 1 | Khaled | 3 |
| 2 | 4 | Doe | 2 |
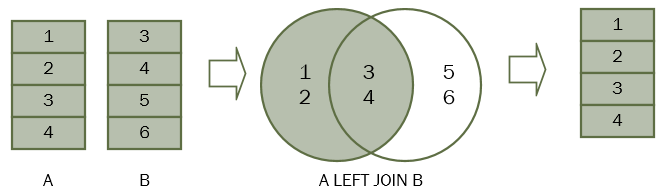
图片来源:https://www.sqltutorial.org/wp-content/uploads/2016/03/SQL-LEFT-JOIN.png
TableA LEFT JOIN TableB 从操作上来讲是说把 TableB 做成一个 Hashmap,然后对应到 TableA 上。和 Inner Join 的不同在于,如果 TableA 中有这个 hashmap 无法对应的 key 怎么办?比如 Employee LEFT JOIN Project 的话,Employee 中的 employee_id = 5 就是 Project 中没有的。首先, employee_id = 5 肯定是要保留的,不会像 INNER JOIN 那样直接忽略。我们可以把 employee_id = 5 那一样的 project_id 定为 NULL。这一点所有的程序都是一样的。不同的是,有的程序 (比如 SQLite) 会把 employee_id 也变成 NULL,但也有程序会把 employee_id = 5 保留,比如 Pandas。
当然,如果 hashmap 中有 TableA 无法对应的 key,那就和 Inner Join 没差别了,这个多出来的 key 和对应的 TableB 中的变量直接忽视。
看结果你就可以理解了:
%%sql
SELECT p.project_id, p.employee_id, e.name, e.experience_years
FROM Employee e
LEFT JOIN Project p
ON p.employee_id = e.employee_id;| project_id | employee_id | name | experience_years |
|---|---|---|---|
| 1 | 1 | Khaled | 3 |
| 2 | 1 | Khaled | 3 |
| 1 | 2 | Ali | 2 |
| 1 | 3 | John | 1 |
| 2 | 4 | Doe | 2 |
| None | None | Alex | 4 |
| project_id | employee_id | name | experience_years |
|---|---|---|---|
| 1 | 1 | Khaled | 3 |
| 1 | 2 | Ali | 2 |
| 1 | 3 | John | 1 |
| 2 | 1 | Khaled | 3 |
| 2 | 4 | Doe | 2 |
TableA LEFT JOIN TableB 和 TableB RIGHT JOIN TableA 是一样的。所以如果你理解了 LEFT JOIN 你也可以理解 RIGHT JOIN。
因为 SQLite 不支持 RIGHT JOIN,下面我会用 Pandas 来演示。
FULL JOIN #
因为 SQLite 不支持 FULL JOIN,下面我会用 Pandas 来演示。
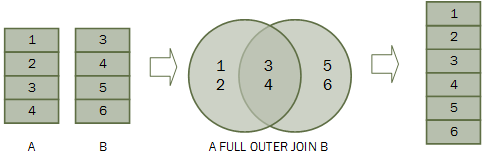
图片来源:https://www.sqltutorial.org/wp-content/uploads/2016/07/SQL-FULL-OUTER-JOIN.png
SELF JOIN #
SQL 有 self join 的功能。其本质就是 inner join: TableA INNER JOIN TableA。
Pandas #
import pandas as pd
# Creating the Project DataFrame
project_data = {
'project_id': [1, 1, 1, 2, 2],
'employee_id': [1, 2, 3, 1, 4]}
project_df = pd.DataFrame(project_data)
# Creating the Employee DataFrame
employee_data = {
'employee_id': [1, 2, 3, 4, 5],
'name': ['Khaled', 'Ali', 'John', 'Doe', 'Alex'],
'experience_years': [3, 2, 1, 2, 4]}
employee_df = pd.DataFrame(employee_data)project_df| project_id | employee_id | |
|---|---|---|
| 0 | 1 | 1 |
| 1 | 1 | 2 |
| 2 | 1 | 3 |
| 3 | 2 | 1 |
| 4 | 2 | 4 |
employee_df| employee_id | name | experience_years | |
|---|---|---|---|
| 0 | 1 | Khaled | 3 |
| 1 | 2 | Ali | 2 |
| 2 | 3 | John | 1 |
| 3 | 4 | Doe | 2 |
| 4 | 5 | Alex | 4 |
Inner Join #
df = pd.merge(project_df, employee_df, how = 'inner', on = 'employee_id')
df| project_id | employee_id | name | experience_years | |
|---|---|---|---|---|
| 0 | 1 | 1 | Khaled | 3 |
| 1 | 1 | 2 | Ali | 2 |
| 2 | 1 | 3 | John | 1 |
| 3 | 2 | 1 | Khaled | 3 |
| 4 | 2 | 4 | Doe | 2 |
Left Join #
df = pd.merge(project_df, employee_df, how = 'left', on = 'employee_id')
df| project_id | employee_id | name | experience_years | |
|---|---|---|---|---|
| 0 | 1 | 1 | Khaled | 3 |
| 1 | 1 | 2 | Ali | 2 |
| 2 | 1 | 3 | John | 1 |
| 3 | 2 | 1 | Khaled | 3 |
| 4 | 2 | 4 | Doe | 2 |
df = pd.merge(employee_df, project_df, how = 'left', on = 'employee_id')
df| employee_id | name | experience_years | project_id | |
|---|---|---|---|---|
| 0 | 1 | Khaled | 3 | 1.0 |
| 1 | 1 | Khaled | 3 | 2.0 |
| 2 | 2 | Ali | 2 | 1.0 |
| 3 | 3 | John | 1 | 1.0 |
| 4 | 4 | Doe | 2 | 2.0 |
| 5 | 5 | Alex | 4 | NaN |
Right Join #
这个和 Left Join 一样。
Full Join #
df = pd.merge(project_df, employee_df, how = 'outer', on = 'employee_id')
df| project_id | employee_id | name | experience_years | |
|---|---|---|---|---|
| 0 | 1.0 | 1 | Khaled | 3 |
| 1 | 2.0 | 1 | Khaled | 3 |
| 2 | 1.0 | 2 | Ali | 2 |
| 3 | 1.0 | 3 | John | 1 |
| 4 | 2.0 | 4 | Doe | 2 |
| 5 | NaN | 5 | Alex | 4 |
最后一次修改于 2025-07-02 • 编辑本页